

「Alexa、こんにちは」「Hey Siri、天気を教えて」——日常的に使っている音声アシスタント。その背後には「音声認識」技術が動いています。
音声認識(ASR:Automatic Speech Recognition)は、人間の音声をAIがテキストに変換する技術です。スマートスピーカー、電話の自動応答、議事録作成ツールなど、あらゆる音声インターフェースの基盤技術となっています。
本記事では、音声認識の仕組みから、主要エンジンの種類、精度を左右する要素、Felo字幕で採用されているMicrosoft Azure音声認識の特徴まで、技術的な背景を徹底解説します。
- 音声認識とは
- 音声認識の仕組み(技術プロセス)
- 主要な音声認識エンジンの種類
- 精度を左右する5つの要素
- Felo字幕で採用されるMicrosoft Azure音声認識
- 音声認識の精度比較
音声認識とは?意味と活用
音声認識(Speech Recognition)とは、マイクホナで集音した音声信号をAIが分析し、対応するテキスト(文字列)を出力する技術です。
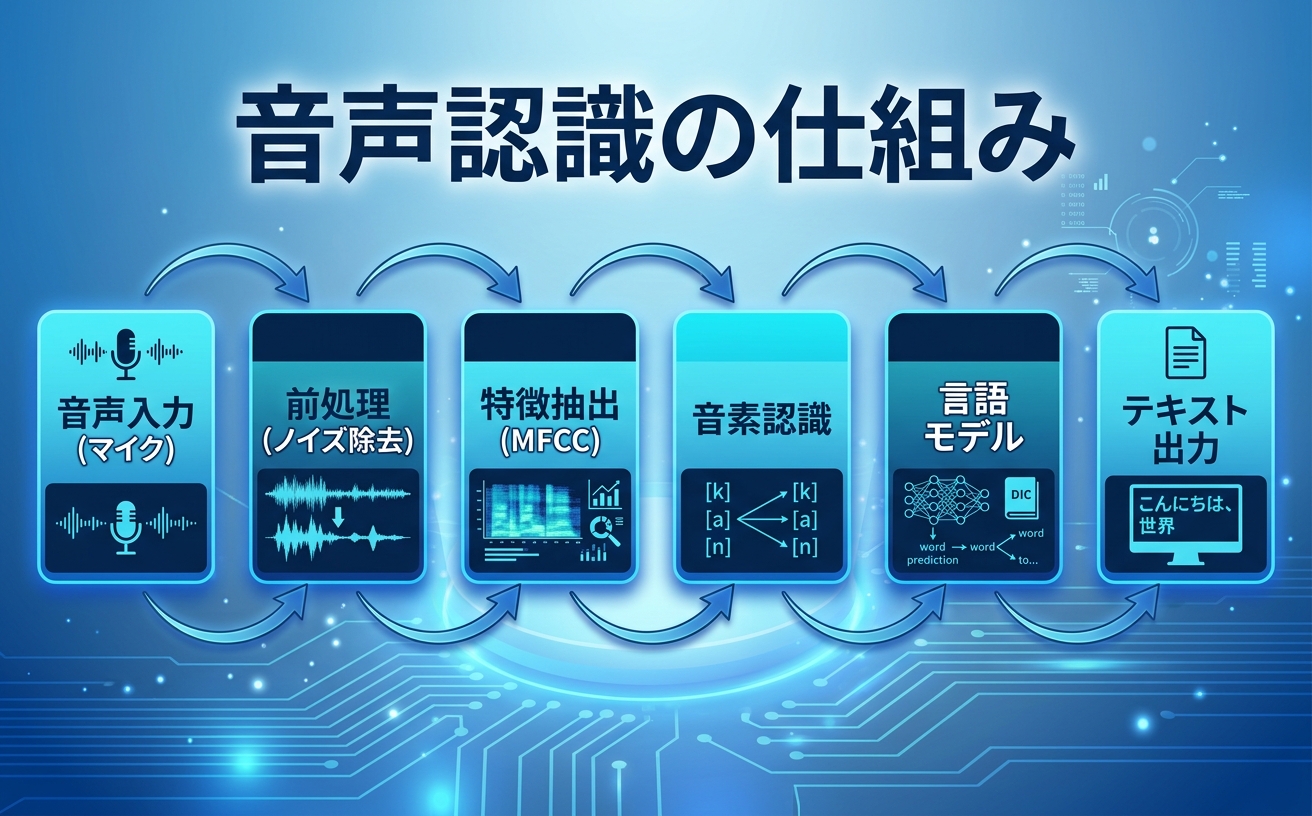
音声認識の基本プロセス:
音声入力 → 前処理 → 特徴抽出 → 音響モデル → 言語モデル → テキスト出力
主な活用領域:
| 領域 | 具体例 | 利用価値 |
|---|---|---|
| スマートスピーカー | Alexa、Google Home | 手ぶらで情報取得 |
| テレビ会議 | Zoom、Teamsの文字起こし | 議事録作成の自動化 |
| 電話自動応答 | コールセンターのIVR | 24時間対応・コスト削減 |
| カーナビ | 音声検索 | 運転中の安全確保 |
| 医療 | 電子カルテ入力 | 医師の負担軽減 |
音声認識の仕組み:技術プロセスを解説
音声認識エンジンは、音声をテキストに変換するために、以下のプロセスを実行します。
ステップ1:音声入力とAD変換
マイクホナで集音したアナログ音声信号を、デジタル信号に変換します。サンプリングレートは通常16kHz(電話品質)または44.1kHz(音楽品質)で行われます。
ステップ2:前処理(ノイズ除去)
音声信号から背景ノイズを除去し、認識精度を向上させます。
処理内容:
– ノイズ抑制(雑音成分の除去)
– エコーキャンセル
– 音量正規化
ステップ3:特徴抽出
音声信号から、AIが判断しやすい「特徴量」を抽出します。伝統的にはMFCC(メル周波数ケプストラム係数)が使用されます。
ステップ4:音響モデルによる音素認識
抽出された特徴量を、音響モデル(Acoustic Model)に入力し、「どの音素(a/i/u/e/o/ka/ki/ku…)」が発話されたかを判定します。
代表的な音響モデル:
– HMM-GMM(隠れマルコフモデル)
– DNN-HMM(深層ニューラルネットワーク)
– Transformer系モデル(最新)
ステップ5:言語モデルによる文章生成
認識された音素列を、言語モデル(Language Model)に入力し、「ありえる単語列」に変換します。
代表的な言語モデル:
– N-gramモデル
– RNN-LSTM
– Transformer(GPT系など)
ステップ6:テキスト出力
最終的なテキストが出力されます。高い精度のエンジンでは、句読点や大文字化も自動的に行われます。
Felo字幕ではMicrosoft Azure Speechを採用し、難聴 文字起こしなどで高い精度を発揮します。
主要な音声認識エンジンの種類
音声認識エンジンは、提供形態によって以下の3種類に大別されます。
タイプ1:クラウドAPI型
代表的なサービス:
– Microsoft Azure Speech Services
– Google Cloud Speech-to-Text
– Amazon Transcribe
– Watson Speech to Text(IBM)
特徴:
– インターネット経由でAPI呼び出し
– 最先進のモデルを利用可能
– 高精度・多言語対応
タイプ2:オンプレミス型
代表的なサービス:
– Julius(オープンソース)
– Kaldi(オープンソース)
– エンタープライズ向け専用サーバー
特徴:
– データを社内に留められる
– カスタマイズ性が高い
– 初期コスト・運用コストが高い
タイプ3:エッジデバイス型
代表的なサービス:
– iOS Siri(オンデバイス処理)
– Android音声認識(オンデバイス処理)
特徴:
– オフラインで動作
– レイテンシが低い
– モデルサイズに制約あり
精度を左右する5つの要素
音声認識の精度は、以下の5つの要素によって大きく左右されます。
要素1:音声品質(入力環境)
影響を与える要因:
– マイクの品質
– 背景ノイズの有無
– 部屋の反響(エコー)
– 発話者とマイクの距離
目安:
– SN比(信号対雑音比)が15dB以上で高精度
– ヘッドセットマイクが最適
要素2:話し方のクリアさ
影響を与える要因:
– 発話速度
– 発音の明瞭さ
– フィラー(「えー」「あのー」)の頻度
– 専門用語・固有名詞の含有
目安:
– 標準的な会話速度(120-150語/分)で最適
– はっきりとした発話で精度向上
要素3:言語・ドメインの対応
影響を与える要因:
– エンジンの言語対応数
– 特定ドメイン(医療・法務など)の学習データ量
– 方言・アクセントへの対応
目安:
– エンタープライズ向けエンジンはビジネス語彙に最適化
要素4:モデルの世代
影響を与える要因:
– DNN系 vs Transformer系
– 学習データの量と質
– モデルのパラメータ数
目安:
– Transformer系モデルが最新の精度ベンチマーク
要素5:カスタマイズの有無
影響を与える要因:
– 専門用語の追加登録(Phrase Hints)
– 業界固有のモデルファインチューニング
– 発話者ごとの適応(Speaker Adaptation)
目安:
– カスタマイズ可能なエンジンで精度5-15%向上
Felo字幕で採用されるMicrosoft Azure音声認識
Felo字幕は、Microsoft Azure Cognitive Services Speech SDKを採用しています。
なぜMicrosoft Azureを選んだのか
| 選択理由 | 内容 |
|---|---|
| 業務用途での実績 | 多数のFortune 500企業が採用 |
| 多言語対応 | 100言語以上、20言語のリアルタイム認識 |
| 専門用語対応 | Phrase Hintsで業界語彙も高精度認識 |
| 安定性 | 99.9%のSLA保証 |
Azure音声認識の核心機能
1. 自動言語検出
発話言語を自動判定。多言語が混在する会議でも、事前設定なしで対応します。
2. 無音検出による自動一時停止
一定時間無音が続くと認識を一時停止。不要な処理・コストを抑制します。
3. 自動再接続・フォールトトレランス
ネットワーク切断時、即座に再接続を試み、5秒間のリトライで復旧します。
4. フレーズヒント(専門用語注入)
カスタム用語リストを事前注入し、専門用語・社名・人名の認識精度を向上させます。
Felo字幕なら、Azure音声認識の精度を体験できます
音声認識エンジンの精度比較
主要な音声認識エンジンの精度(語誤り率:WER)を比較しました。
一般的な精度比較
| エンジン | 英語WER | 日本語WER | 特徴 |
|---|---|---|---|
| Microsoft Azure | 5-8% | 8-12% | エンタープライズ向け高精度 |
| Google Cloud | 6-10% | 10-15% | 多言語対応が充実 |
| Amazon Transcribe | 7-12% | 12-18% | コストパフォーマンス |
| Whisper(OpenAI) | 4-6% | 6-10% | オープンソースで高精度 |
WER(Word Error Rate)は低いほど高精度
Felo字幕の精度
Felo字幕はMicrosoft Azure Speechを採用しているため、標準的なビジネス会議で以下の精度を実現しています。
| 言語 | 期待される精度 | 条件 |
|---|---|---|
| 日本語 | 90-95% | クリアな発話・ノイズ少的環境 |
| 英語 | 92-97% | ネイティブスピーカー |
| 中国語 | 88-93% | 標準語・北京語 |
音声認識の未来動向
音声認識技術は、以下の方向で進化しています。
1. 生成AIとの統合
GPT-4などのLLMと音声認識を統合し、単なる文字起こし以上の価値を提供。
具体例:
– 要約の自動生成
– 意図分析・タスク抽出
– 感情分析
2. マルチモーダル認識
音声だけでなく、映像・テキスト・スライドを統合的に認識。
3. パーソナライズされた認識
個人の発話特性に学習・適応し、精度を向上。
よくある質問(FAQ)
Q1: 音声認識と音声合成の違いは?
A: 音声認識は「音声→テキスト」、音声合成は「テキスト→音声」です。両方を組み合わせることで、音声対話システムを実現できます。
Q2: 日本語と英語ではどちらが認識精度が高い?
A: 一般的に英語の方が精度が高い傾向にあります。これは、日本語の漢字・仮名混じり文の構造的複雑さや、同音異義語の多さによるものです。
Q3: 音声認識はオフラインで使える?
A: エッジデバイス型(スマホのオフライン機能など)であれば可能です。ただし、精度はクラウド型より劣る傾向にあります。
Q4: 方言やアクセントには対応している?
A: 主要な音声認識エンジンは、標準的な発話に最適化されています。方言や強いアクセントでは精度が低下する可能性があります。
Q5: 音声認識の精度を上げるには?
A: 以下の対策が有効です:
– クリアな発話を心がける
– 高品質なマイクを使う
– ノイズの少ない環境で話す
– 専門用語を事前登録する(Phrase Hints)
まとめ:音声認識の仕組みを理解して活用
音声認識技術は、スマートスピーカー、テレビ会議、電話応用など、あらゆる音声インターフェースの基盤となっています。
本記事で解説した通り、音声認識の精度は、エンジンの選択、入力環境、話し方など、複数の要素によって左右されます。
Felo字幕は、Microsoft Azureというエンタープライズグレードの音声認識エンジンを採用することで、安定した高精度な文字起こしを実現しています。
関連記事: